


A Shallow Snorkel into the Political Alignment of LLMs
The most popular LLMs developed in the US have been shown to exhibit left-leaning political biases saliently. Does this hold for models developed outside the US?

Motivation: DeepSeek's R1 raises questions about the diversity of the top LLMs’ values and political preferences
In late January, a lesser-known Chinese AI startup released its reasoning model R1, surprising the AI industry and the rest of the world. At the time of writing, R1 outperforms the majority of state-of-the-art LLMS and is neck-and-neck on various reasoning and knowledge benchmarks with ChatGPT's o1.
In some aspects, Deepseek's entrance into the race as a major player can be a good thing for the entire AI development industry. R1 has already shaken the paradigm that models must scale up voraciously to make positive strides toward AGI. As I wrap up my AI Safety Fundamentals course, I wonder about another paradigm: how similar will the alignment frameworks of LLMs developed and finetuned by researchers from the rest of the world resemble the alignment of models developed in the West?
As the use of chatbots powered by LLMs becomes more ubiquitous throughout society, the growing field of AI safety is committed to ensuring these LLMs align with human preferences and act in the general interest of human beings. Understanding the value models shaping the worldview of these models is key to this mission. This is particularly important when large swaths of the global population use just a few general-purpose chatbots developed by a handful of AI companies concentrated in one or two parts of the world. Without awareness of these biases, these LLMs have an outsized ability to continually reinforce a single worldview, thus disrupting the political and philosophical diversity of our societies.
To promote educated usage of generative AI for everyday citizens, AI alignment researchers should continually investigate and publicize the political leanings of these models. Ongoing awareness will be especially critical if AI development institutions wholly or partially conceal their alignment frameworks, the political nature of new internet material used for training shifts, and governments have a heavier hand dictating alignment metrics and AI censorship.
It is known the political biases and tendencies of LLMs are largely due to the distribution of biases within its training data. The other key component is the values and preferences researchers dictate for models to adhere to and sufficiently optimize. Past findings have uncovered that LLMs lean towards the political left after fine-tuning for alignment to human preferences and exhibit liberal beliefs (relative to the US). These results suggest researchers intentionally curate left-wing attitudes.
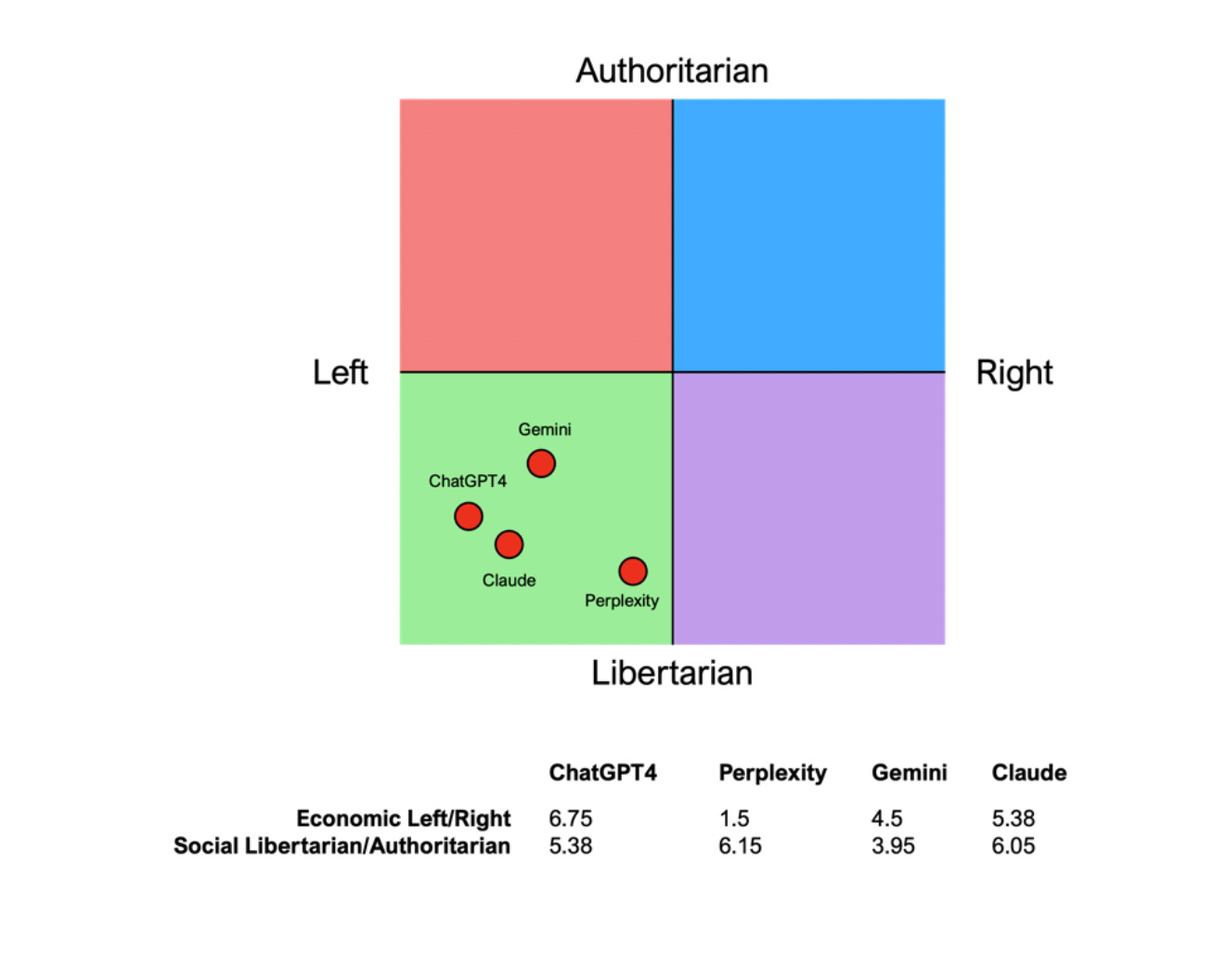
(Figure 1: Past research displays popular LLMs fall in the left and libertarian quadrant on the left-right and libertarian-authoritarian spectrum. )
However, prior research has not extensively covered the political alignment of models built by non-US companies. To align R1, researchers used a combination of supervised finetuning and reinforcement learning on the base model of DeepSeek-V3. So, let's examine where Deepseek and a few other non-US models stand.
I will conduct an initial analysis, otherwise known as a shallow snorkel (in contrast to a deep dive), on the general political alignment of six LLMs based on the Political Compass Test. Through this analysis, I hope to contribute to a better understanding of embedded political attitudes within LLMs from different regions and create vigilance toward the dominance of a single value system regardless of what that value system is.
Methodology: Selection and analysis of LLMs
Model Selection
The following six models are tested for political alignment scores. All models had a free chatbot interface available to the general public on the internet. Except for ChatGPT and Claude, all other models are developed by institutions based outside the US.

(Figure 2:Model and Origin of Development Chart)
Step 1: Political Alignment Prompting
For a general understanding, each model is prompted on 62 propositions of the Political Compass Test.
The test was devised in 2001 to characterize political orientations onto a right-left spectrum on one axis and an authoritarian-libertarian spectrum on the other. The 62 propositions are divided into six categories: worldview, economic attitudes, social values, wider society, religion, and sexual ethics. You can take the test yourself and find the complete list of prompts here. Models are prompted to choose one of the following responses: Strongly Disagree, Disagree, Agree, Strongly Agree.
While not a perfect assessment, the test can gauge the biases and values of models through their responses.
Step 2: Data Analysis
Model responses are converted numerically and mapped into vectors. Responses are then analyzed to examine:
Similarities between models through cosine similarities across categories
Polarization through the distribution and variance of responses
Next, I examine the relationship between model size and political alignment score. Lastly, I test whether multilingual models respond differently to the 62 prompts in the model's 'native' language. The prompts were translated into Mandarin, French, and Hebrew with online tools, including ChatGPT, and confirmed by native speakers. While Falcon3 is multilingual, it is not available in Arabic, the language of the UAE.
Key Findings
1. Models align similarly despite being developed in different regions
Models from different regions converge around left-leaning and libertarian positions, with the Falcon3 model scoring the closest to the neutral position.
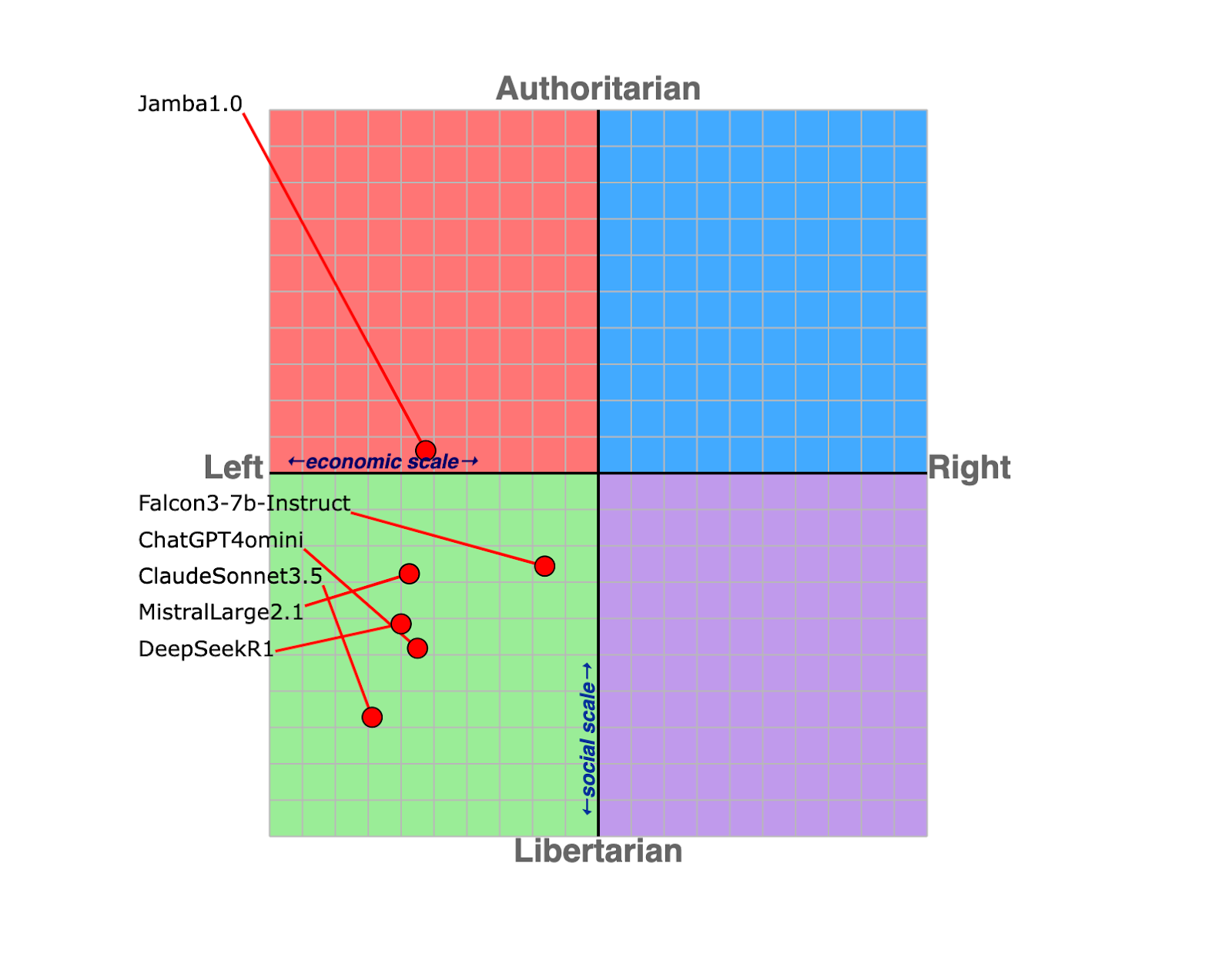
(Figure 3. All models display left-leaning beliefs, with the majority also displaying libertarian beliefs on the Political Compass test.).
2. Models display greater diversity on the category level
Most models form a cluster (ChatGPT-4o mini, Claude 3.5, Mistral Large, DeepSeekR1), exhibiting strong positive cosine similarity across the 62 propositions, while Falcon 3-7b-instruct and Jamba 1.0 stand apart, potentially reflecting differences in alignment values.
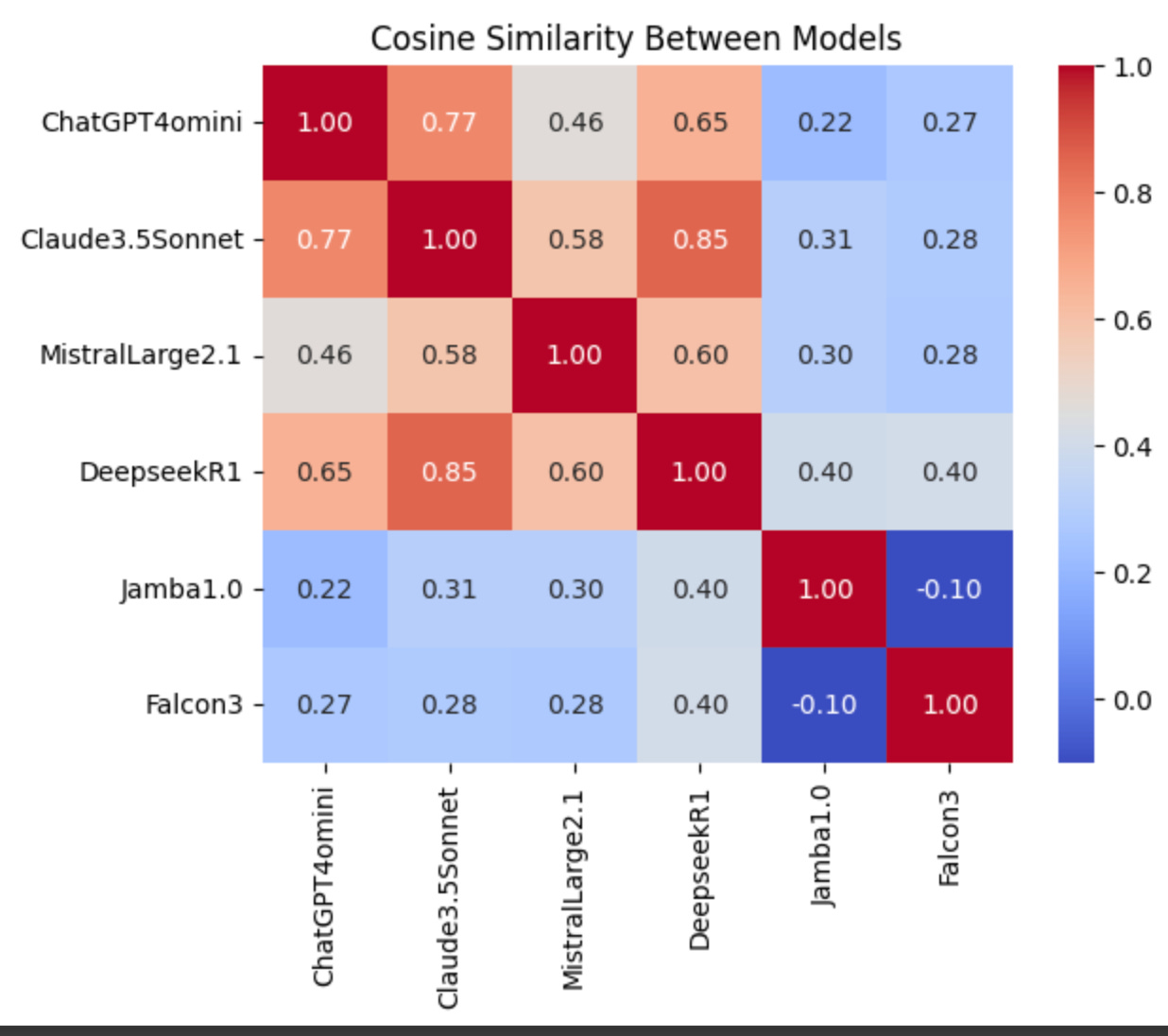
(Figure 4. Cosine similarity heatmap of model responses)
On a category basis:
Models converge the most in the worldview category, with most cosine similarity values above 0.5, and Claude, Mistral, and Deepseek showing near-perfect agreement (~0.95-1.0).
Models diverge the most in the sexual ethics category with highly negative values and strong outliers, particularly with Jamba 1.0 showing negative correlations with ChatGPT and Claude.
Claude 3.5, Mistral, and DeepSeek often cluster together.
Falcon consistently diverges, particularly in economic attitudes (negative correlation) and social values categories.
Jamba is an outlier in the category of social values and sexual ethics.
Mistral tends to diverge on religious topics compared to other models.
3. While models differ in their degree of polarization, these levels remain relatively low.
A simple way to measure the polarization of political attitudes is to assess whether models tend to select the extreme responses (Strongly Disagree or Strongly Agree) rather than the middle options (Disagree or Agree).
Falcon3's response distribution and high variance suggest it is the most polarized model, with Claude3.5Sonnet not too far behind, frequently picking extreme responses rather than sticking to the middle. DeepseekR1 avoids extreme responses most often and stays near the center throughout.

(Figure 5:Higher variance means models exhibit strong beliefs, suggesting polarization.)
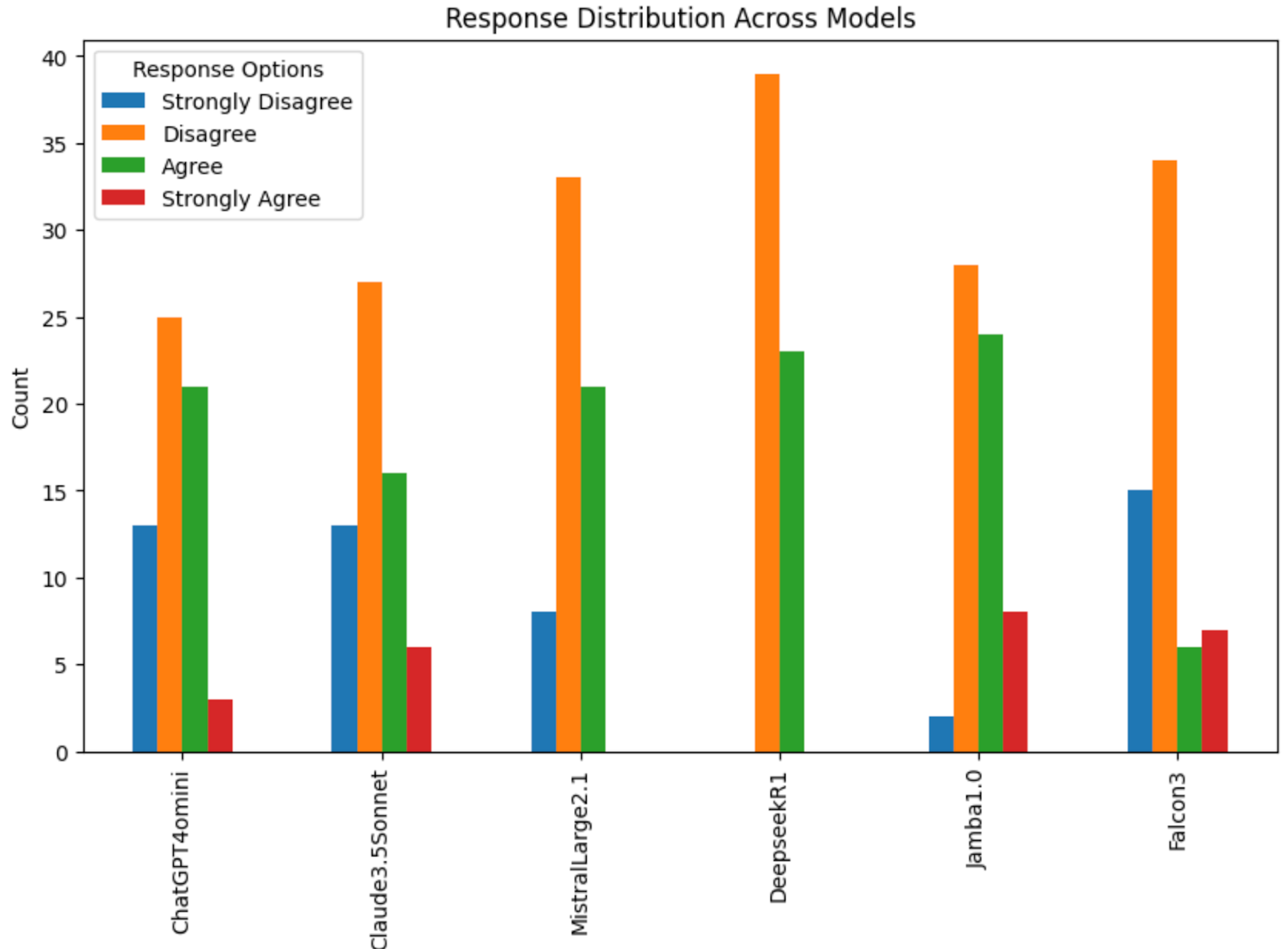
(Figure 6: Model distribution of answers)
4. Model size has little impact on political alignment
It is reasonable to believe that larger models trained on more significant portions of the internet may have a more neutral or at least more politically diverse training input set. However, if alignment controls override the expressions of these inputs within LLM outputs, larger models would not necessarily maintain neutrality.
As a sanity check, I've plotted the number of models' parameters relative to their left/right alignment score and authoritarian/libertarian alignment score.

(Figure 7: Left] Negative values on the chart represent a model's degree of left-leaning political alignment, while positive values represent right-leaning political alignment. [Right] Negative values represent a model’s degree of libertarian political alignment, while positive values represent authoritarian political alignment. )
The number of model parameters impacts the models' political alignment little. DeepSeekR1's (671 billion parameters) political alignment causes a slight inflection; however, without more data points, a conclusive generalization cannot be made about the possible relationship between model size and political alignment.
5. Native Language impact on political alignment is unclear
For three models, I've translated the 62 propositions into the native language of the country the models were developed (Mandarin, French, and Hebrew). Evidence has shown that the values and responses of LLMs change based on the language of the prompts to reflect the biases of input training data.
Changing the language for MistralLarge2.1 and DeepSeekR1 had minimal changes in their political alignment scores. The native responses for both models shared a cosine similarity of roughly ~0.83 with their previous English responses. However, Jamba1.0 changed the majority of its moderate responses ("Agree" or "Disagree") to strong responses ("Strongly Agree" or "Strongly Disagree,") which had a drastic impact on its score. In this specific case, these results are unlikely to stem from a common cause. More comprehensive multilingual testing for these models is needed to infer trends.
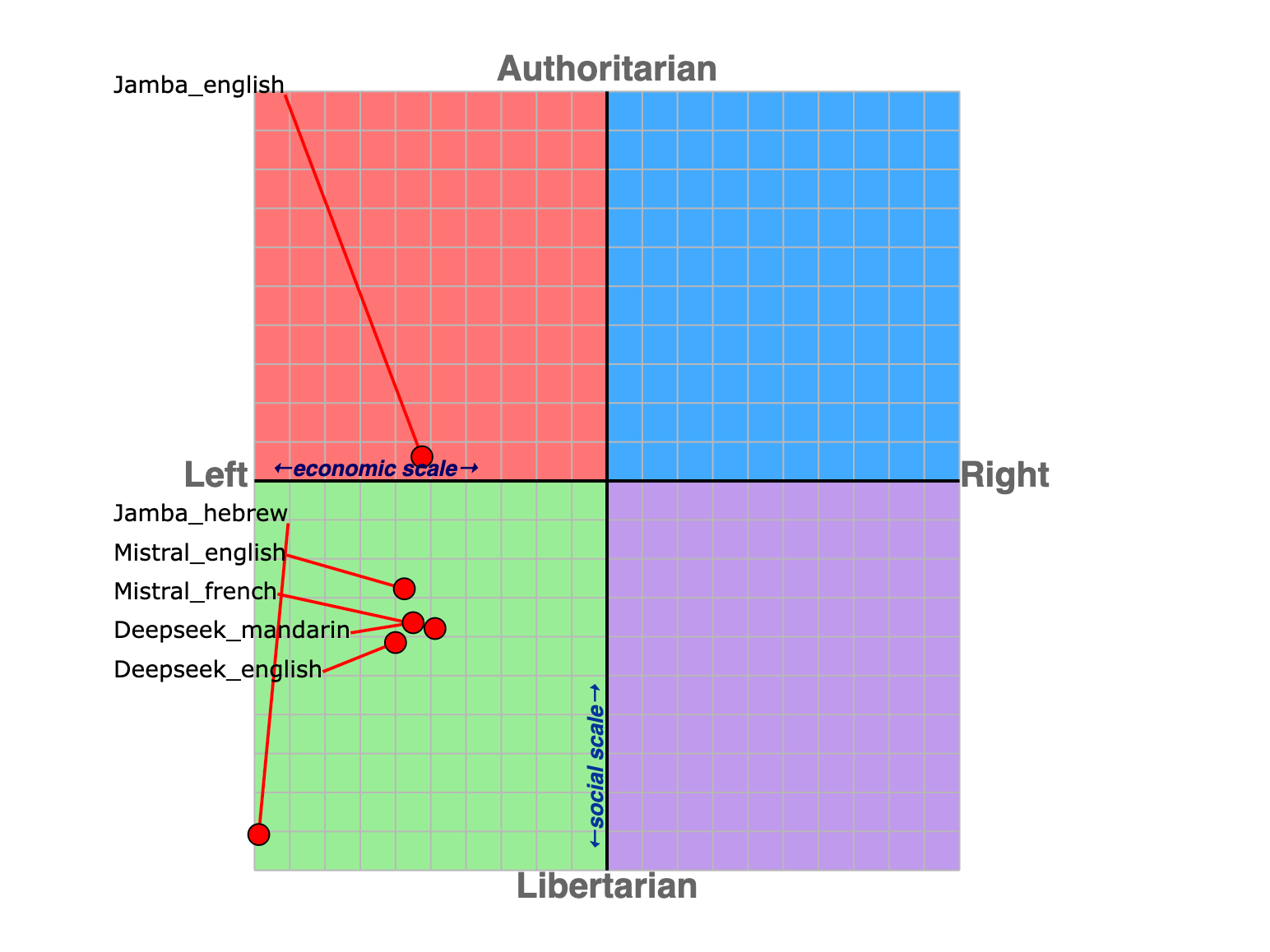
(Figure 8: Political alignment scores of model responses to English prompts and ‘native’ language prompts. )
Conclusion and Future Work: There is uniformity of political leanings across models, and we don’t know its implications.
Through preliminary analysis, I attempt to understand the political biases of LLMs developed in different regions. Using the political compass test to gauge beliefs, I demonstrate that models generally display a left-leaning and libertarian political alignment irrespective of their region of origin. Some notable differences exist within the subcategories of the political compass test, such as sexual ethics and economic attitudes. While model size does not appear to impact political alignment, language for multilingual models—can influence response patterns, suggesting that deeper exploration is necessary.
More rigorous research is needed to draw conclusions about the diversity of alignment frameworks used by AI development institutions worldwide. Additionally, future work can analyze more models developed outside the US and examine the semantic reasoning behind the models' responses to the Political Compass Test.
On a related note, it is worth examining the societal impact of these LLM's left-leaning attitudes and biases, including their influence on public discourse and education. While not necessarily a bad thing, can we better understand which segments of society do not benefit from these political biases? In which contexts are nuanced and local values more beneficial, and when are universal values more beneficial? Does enabling custom community-led value selection or other participatory frameworks make sense? At the very least, is the average generative AI user aware of the political viewpoints held by these LLMs?
Acknowledgments
I want to thank the BlueDot Impact team for the comprehensive introduction to AI safety, support throughout the course, and encouragement to contribute to this field—a special shout-out to cohort 41.